# 文章导图
# 前端框架
# Vue
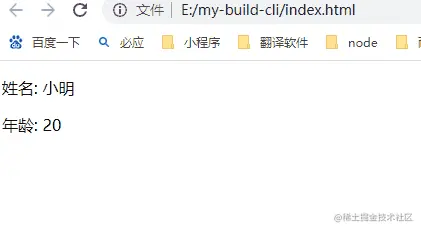
# 手写minni版的MVVM框架
实现效果:2s后修改姓名和年龄这两个值,页面响应式更新渲染
# 实现流程
- 实现 observer函数,利用Object.defineProperty把data中的属性变成响应式的,同时给每一个属性添加一个dep对象(用来存储对应的watcher观察者)
- 定义compile函数,模板编译,遍历DOM,遇到mustache(双大括号{{}})形式的文本,则替换成data.key对应的值,同时将该dom节点添加到对应key值的dep对象中
- 当data的数据变化时,调用dep对象的update方法,更新所有观察者中的dom节点
<!doctype html>
<head>
<meta charset="UTF-8">
<title>vue的mvvm简单实现</title>
</head>
<div id="app">
<p>姓名: <span>{{name}}</span></p>
<p>年龄: <span>{{age}}</span></p>
</div>
<script>
window.onload = function() {
// new一个vue实例
let vue = new Vue({
el: '#app',
data: {
name: '加载中',
age: '18'
}
})
// 2s后更新页面信息
setTimeout(() => {
// 修改vue中$data的name和age属性
vue.$data.name = '小明';
vue.$data.age = 20
}, 1000)
}
class Vue {
constructor(options) {
this.options = options;
this.$data = options.data;
this.observe(options.data);
this.compile(document.querySelector(options.el))
}
// 监听data中属性变化
observe(data) {
Object.keys(data).forEach(key => {
// 给data中的每一个属性添加一个dep对象(改对象用来存储对应的watcher观察者)
let observer = new Dep();
// 利用闭包 获取和设置属性的时候,操作的都是value
let value = data[key];
Object.defineProperty(data, key, {
get() {
// 观察者对象添加对应的dom节点
Dep.target && observer.add(Dep.target);
return value;
},
set(newValue) {
value = newValue;
// 属性变化时,更新观察者中的所有节点
observer.update(newValue)
}
})
})
}
compile(dom) {
dom.childNodes.forEach(child => {
// nodeType为3时是文本节点,并且该节点的内容包含`mustache`(双括号)
if(child.nodeType === 3 && /\{\{(.*)\}\}/.test(child.textContent)) {
// RegExp.$1是正则表达式匹配的第一个字符串,这里对应的就是data的key值
let key = RegExp.$1.trim();
// 将该节点添加到对应的观察者对象中,在下面的this.options.data[key]中触发get方法
Dep.target = child;
// 将{{key}}替换成data中对应的值
child.textContent = child.textContent.replace(`{{${key}}}`, this.options.data[key]);
Dep.target = null;
}
// 递归遍历子节点
if(child.childNodes.length) {
this.compile(child)
}
})
}
}
// dep对象存储所有的观察者
class Dep {
constructor() {
this.watcherList = [];
}
// 添加watcher
add(node) {
this.watcherList.push(node);
}
// 更新watcher
update(value) {
this.watcherList.forEach(node => {
node.textContent = value;
})
}
}
</script>
</html>
50行代码的MVVM,感受闭包的艺术 (opens new window)
# 手写v-model数据双向绑定
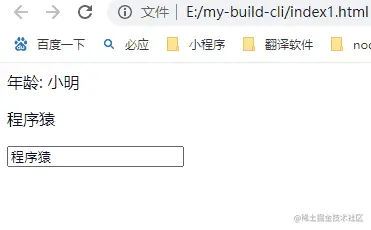
# 和前文mini版MVVM框架的区别
- 实现v-model指令,input值改变后,页面对应的数据也会变化,实现数据的双向绑定
- 给input元素绑定input事件,当输入值变化会触发对应属性的dep.update方法,通过对应的观察者发生变化
- 增加了数据代理,通过this.info.person.name就可以直接修改$data对应的值,实现了this对this.$data的代理
- 数据劫持,对data增加了递归和设置新值的劫持,让data中每一层数据都是响应式的,如info.person.name
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>vue双向绑定的简单实现</title>
</head>
<body>
<div id="app">
<div>年龄: <span>{{info.person.name}}</span></div>
<p>{{job}}</p>
<input v-model="job" placeholder="请输入工作" type="text">
</div>
<script>
window.onload = function() {
// new一个vue对象
let vm = new Vue({
// el为需要挂在的dom节点
el: '#app',
data: {
info: {
person: {
name: '加载中'
}
},
job: '程序猿'
}
})
setTimeout(() => {
vm.info.person.name = '小明'
}, 2000)
}
class Vue {
constructor(options) {
this.$data = options.data;
this.$el = document.querySelector(options.el);
observe(options.data);
this.proxy(this.$data, this);
this.compile(this.$el, this)
}
// 模板编译
compile(dom, vm) {
Array.from(dom.childNodes).forEach(child => {
// 元素节点,匹配v-model 如input,textArea元素等
if(child.nodeType === 1) {
Array.from(child.attributes).forEach(attr => {
// 判断元素是否设置v-model属性
if(attr.name.includes('v-model')) {
Dep.target = child;
child.value = vm.$data[attr.value];
Dep.target = null;
// 重点:给input绑定原生input事件
child.addEventListener('input', e => {
// 当input输入内容发生变化时,动态设置vm.$data[attr.value]的值
vm.$data[attr.value] = e.target.value;
})
}
})
}
if (child.nodeType === 3 && /\{\{(.*)\}\}/.test(child.textContent)) {
let key = RegExp.$1.trim()
let keyList = key.split('.')
let value = vm.$data
Dep.target = child
// 循环遍历,找到info.person.name对应的name值
keyList.forEach(item => {
value = value[item]
})
Dep.target = null
child.textContent = child.textContent.replace(`{{${key}}}`, value)
}
if (child.childNodes.length > 0) {
// 递归模板编译
this.compile(child, vm)
}
})
}
// this 代理this.$data;
// vm.info.person.name 相当于 vm.$data.info.person.name
proxy($data, vm) {
Object.keys($data).forEach(key => {
Object.defineProperty(vm, key, {
set(newValue) {
$data[key] = newValue;
},
get() {
return $data[key]
}
})
})
}
}
function observe(data) {
if(data && typeof data === 'object') {
return new Observe(data);
}
}
// 递归进行数据劫持,使data中的每一层都是响应式
function Observe(data) {
Object.keys(data).forEach(key => {
let value = data[key];
let dep = new Dep();
// 递归
observe(value);
Object.defineProperty(data, key, {
get() {
Dep.target && dep.add(Dep.target);
return value;
},
set(newValue) {
value = newValue;
// 如果新设置的值是一个对象,该对象也要变成响应式的
observe(newValue);
dep.update(newValue)
}
})
})
}
class Dep {
constructor() {
this.subs = [];
}
add(target) {
this.subs.push(target);
}
update(newValue) {
this.subs.forEach(node => {
if(node.tagName === 'INPUT' || node.tagName === 'TEXTAREA') {
node.value = newValue;
} else {
node.textContent = newValue;
}
})
}
}
</script>
</body>
</html>
# 使用proxy实现数据监听
vue3底层通过Proxy实现了数据监听,替代了vue2中的Object.defineProperty
function observe(target) {
return new Proxy(target, {
get(target, key, receiver) {
let result = Reflect.get(target, key);
// 递归获取对象多层嵌套的情况,如pro.info.type(递归监听,保证每一层返回都是proxy对象)
return isObject(result);
},
set(target, key, value, receiver) {
if(key !== 'length') {
// 解决对数组修改,重复更新视图的问题
console.log('更新视图')
}
return Reflect.set(target, key, value, receiver)
}
})
}
function isObject(target) {
if(typeof target === 'object' && target !== null) {
return observe(target);
} else {
return target;
}
}
let target = {name: '测试', info: { type: '1' }}
let pro = observe(target);
pro.infot.type = 2;
# vue异步更新原理
vue的数据频繁变化,但为什么dom只会更新一次
- Vue数据发生变化之后,不会立即更新dom,而是异步更新的
- 侦听到数据变化,Vue将开启一个队列,并缓存在同一事件循环中发生的所有数据变更
- 如果同一个watcher被多次触发,只会被推入队列中一次,可以避免重复修改相同的dom,这种去掉重复数据,对于避免不必要的计算和DOM操作是非常重要的
- 同步任务执行完毕,开始执行异步watcher队列任务,一次性更新DOM
异步更新的源码实现
// 定义watcher类
class Watcher {
update() {
// 放到watcher队列中,异步更新
queueWatcher(this);
}
// 触发更新
run() {
this.get();
}
}
// 队列中添加watcher
function queueWatcher(watcher) {
const id = watcher.id;
// 先判断watcher是否存在,去掉重复的watcher
if(!has[id]) {
queue.push(watcher);
has[id] = true;
if(!pending) {
pending = true;
// 使用异步更新watcher
nextTick(flushSchedulerQueue)
}
}
}
let queue = []; // 定义watcher队列
let has = {}; // 使用对象来保存id,进行去重操作
let pending = false; // 如果异步队列正在执行,将不会再次执行
// 执行watcher队列任务
function flushSchedulerQueue() {
queue.forEach(watcher => {
watcher.run();
if(watcher.options.render) {
// 在更新之后执行对应的回调:这里是updated钩子函数
watcher.cb();
}
})
// 执行完成后清空队列 充值pending状态
queue = [];
has = {};
pending = false;
}
# nextTick为什么要优先使用微任务实现
vue nextTick的源码实现,异步优先级判断,总结就是Promise > MutationObserver > setImmediate > setTimeout
优先使用Promise,因为根据event loop与浏览器更新渲染时机,宏任务->微任务->渲染更新,使用微任务,本次event loop轮训就可以获取到更新的dom
如果使用宏任务,要到下一次event loop中,才能获取到更新dom
nextTick的源码实现
// 定义nextTick的回调队列
let callbacks = [];
// 批量执行nextTick的回调队列
function flushCallbacks() {
callbacks.forEach(cb => cb());
callbacks = [];
pending = false;
}
// 定义异步方法,优先使用微任务实现
let timerFunc;
// 优先使用promise 微任务
if(promise) {
timerFunc = function() {
return Promise.resolve().then(flushCallbacks);
}
}
// 如果不支持promise,在使用MutationObserver 微任务
else if(MutationObserver) {
const textNode = document.createTextNode('1');
const observer = new MutationObserver(() => {
flushCallbacks();
observer.disconnect();
})
const observer = observer.observe(textNode, { characterData: true })
textNode.textContent = '2'
}
// 微任务不支持,在使用宏任务实现
else if(setImmediate) {
timerFunc = function() {
setImmediate(flushCallbacks)
}
} else {
timerFunc = function() {
setTimeout(flushCallbacks)
}
}
// 定义nextTick方法
export function nextTick(cb) {
callbacks.push(cb);
if(!pending) {
pending = true;
timerFunc();
}
}
你真的理解$nextTick么 (opens new window)
Vue 源码详解之 nextTick:microtask 才是核心! (opens new window)
# computed 和 watch的区别
- 计算属性本质上是computed watcher,而watch本质是user watcher(用户自己定义的watcher);
- computed有缓存的功能,通过dirty控制
- watcher设置deep:true,实现深度监听的功能
- computed可以监听多个值的变化
# computed原理
- 初始化计算属性时,遍历computed对象,给其中每一个计算属性分别生成唯一computed watcher,并将该watcher中的dirty设置为true 初始化时,计算出现并不会立即计算(vue做的优化之一),只有当获取的计算属性值才会进行对应计算
- 初始化计算属性时候,将Dep.target设置成当前的computed watcher,将computed watcher添加到所依赖data值的dep中(依赖收集过程),然后计算computed对应的值,后将dirty改成false
- 当依赖data中的值发生变化时,调用set方法触发dep的notiry方法,将computed watcher中的dirty设置为true
- 下次获取计算属性值时,若dirty为true,重新计算属性值
- dirty是控制缓存的关键,当所依赖的data发生变化,dirty设置为true,再次呗获取时,就会重新计算 computed源码实现
// 空函数
const noop = () => {};
// computed初始化的watcher传入lazy:true,就会触发watcher中的dirty值为true
const computedWatcherOptions = { lazy: true }
// Object.defineProperty 默认value参数
const sharedPropertyDefinition = {
enumberable: true,
configurable: true,
get: noop,
set: noop
}
// 初始化computed
class initComputed {
constructor(vm, computed) {
// 新建存储watcher对象,挂载在vm对象执行
const watchers = (vm._computedWatchers = Object.create(null));
// 遍历computed
for(const key in computed) {
const userDef = computed[key];
// getter值为computed重key的监听函数或对象的get值
let getter = typeof userDef === 'function' ? userDef : userDef.get;
// 新建computed watcher
watchers[key] = new Watcher(vm, getter,noop, computedWatcherOptions);
if(!(key in vm)) {
// 定义计算属性
this.defineComputed(vm, key, userDef)
}
}
}
// 重新定义计算属性 对get和set劫持
// 利用Object.defineProperty来对计算属性的get和set进行劫持
defineComputed(target, key, userDef) {
// 如果是一个函数,需要手动赋值到get上
if (typeof userDef === "function") {
sharedPropertyDefinition.get = this.createComputedGetter(key);
sharedPropertyDefinition.set = noop;
} else {
sharedPropertyDefinition.get = userDef.get
? userDef.cache !== false
? this.createComputedGetter(key)
: userDef.get
: noop;
// 如果有设置set方法则直接使用,否则赋值空函数
sharedPropertyDefinition.set = userDef.set ? userDef.set : noop;
}
Object.defineProperty(target, key, sharedPropertyDefinition);
}
// 计算属性的getter 获取计算属性的值时会调用
createComputedGetter(key) {
return function computedGetter() {
// 获取对应的计算属性watcher
const watcher = this._computedWatchers && this._computedWatchers[key];
if (watcher) {
// dirty为true,计算属性需要重新计算
if (watcher.dirty) {
watcher.evaluate();
}
// 获取依赖
if (Dep.target) {
watcher.depend();
}
//返回计算属性的值
return watcher.value;
}
};
}
}
# watch原理
- 遍历watch对象,给其中每一个watch属性,生成use watcher
- 调用watcher中的get方法,将Dep.target设置成当前的user watcher,并将user watcher添加到监听data值对应的dep中(依赖收集的过程)
- 当所监听data中的值发生变化时,会调用set方法触发dep的notify方法,执行watcher中定义的方法
- 设置成deep:true的情况,递归遍历所监听的对象,将user watcher添加到对象中每一层key值的dep对象中,这样武林当对象的中那一层发生变化,watcher都可以监听到。通过对象的递归遍历,实现了深度监听功能
Vue.js的computed和watch是如何工作的? (opens new window)
手写Vue2.0源码(十)-计算属性原理 (opens new window)
珠峰:史上最全最专业的Vue.js面试题训练营 (opens new window)
# vue css scoped
# css属性选择器示例
<!-- 页面上"属性选择器"这几个字显示红色 -->
<div data-v-hash class="test-attr">属性选择器</div>
<style>
/* 该标签有个data-v-hash的属性,只不过该属性为空,依然可以使用属性选择器 */
.test-attr[data-v-hash] {
color: red
}
</style>
<script>
// 通过js判断是否存在data-v-hash属性
console.log(document.querySelector('.test-attr').getAttribute('data-v-hash') === '') // true
</script>
# vue css scoped原理
编译时,会给每个vue文件生成一个唯一的id,会将次id添加到当前文件中所有html标签上
如<div class="demo"></div>会被编译成<div class="demo" data-v-27e4e96e></div>
编译style标签时,会将css选择器改造成属性选择器,如.demo{color: red}会被编译成.demo[data-v-27e4e96e]{color: red}
# 虚拟DOM
什么是虚拟dom?
Virtual DOM是模拟真实DOM节点,这个对象就是更加轻量级的对DOM的描述
为什么现在主流的框架都是用虚拟dom?
- 前端性能优化的一个秘诀就是尽可能少操作DOM,频繁变动DOM会造成浏览器的回流或者重绘
- 是用虚拟dom,当数据变化,页面需要更新时,通过diff算法,对比新旧虚拟dom节点进行对比,比较两棵树的差异,生成差异对象,一次性将dom进行批量更新操作,进而有效提高性能
- 虚拟DOM本质上是JS对象,而DOM与平台强相关,相比之下虚拟DOM可以进行更方便的跨平台操作,例如服务器渲染、weex开发等等
# 虚拟dom与真实dom的相互转化
// 将真实dom转化为虚拟dom
function dom2Json(dom) {
if(!dom.tagName) return;
let obj = {};
obj.tag = dom.tagName;
obj.children = [];
dom.childNodes.forEach(item => {
// 去掉空节点
dom2Json(item) && obj.children.push(dom2Json(item));
})
return obj
}
// 虚拟dom包含三个参数 type,props, children
class Element {
this.type = type;
this.props = props;
this.children = children;
}
// 将虚拟dom渲染成真实的dom
function render(domObj) {
let el = document.createElement(domObj.type);
Object.keys(domObj.props).forEach(key => {
let value = domObj.props[key];
switch(key) {
case 'value':
if(el.tagName == 'INPUT' || el.tagName == 'TEXTAREA') {
el.value = value;
} else {
el.setAttribute('value', value);
}
break;
case 'style':
el.style.cssText = value;
break;
default:
el.setAttribute(key, value)
}
})
domObj.children.forEach(child => {
// child = child instaceof Element ? render(child) : document.createTextNode(child);
el.appendChild(render(child))
})
return el;
}
让虚拟DOM和DOM-diff不再成为你的绊脚石 (opens new window)
虚拟 DOM 到底是什么? (opens new window)
详解vue的diff算法 (opens new window)
# vuex原理
- vuex中store本质就是一个没有template模板的隐藏式的vue组件
- vuex是利用vue的mixin混入机制,在beforeCreate钩子前混入vuexInit方法
- vuexInit方法实现将vuex store注册到当前组件的$store属性上
- vuex的state作为一个隐藏的vue组件的data,定义在state上面的变量,相当于这个vue示例的data属性,凡是定义在data上的数据都是响应式的
- 当页面中使用了vuex state中的数据,就是依赖收集的过程,当vuex中state的数据发生变化,就通过调用对应的dp对象notify方法 去修改视图变化
# vue-router原理
- 创建的页面路由会与该页面形式一个路由表(key value形式,key为该路由,value为对应页面)
- vue-router原理是监听URL的变化,然后匹配路由规则,会用新路由的页面替换到老页面,无需刷新
- 目前单页面使用的路由有两种实现方式:hash模式、history模式
- hash模式(路由中带#号),通过hashChange时间来监听路由变化 window.addEventListener('hashChange', ()=> {})
- history模式,利用了pushState()和replaceState()方法,实现往history中添加新的浏览记录、或替换对应的浏览器记录,通过popstate事件来监听路由变化,window.addEventListener('popstate', () => {})
前端路由简介以及vue-router实现原理 (opens new window)
Vue Router原理 (opens new window)
# vue3和vue2的区别
vue3性能比vue2.x快1.2~2倍
使用proxy取代Object.defineProperty,解决了vue中新增属性监听不到的问题,同时proxy也支持数组,不需要像vue2那样对数组的方法做拦截处理
diff方法优化--vue3新增了静态标记(patchflag),虚拟节点对比时,就只会对比这些带有静态标记的节点
静态提升
vue3对于不参与更新的元素,会做静态提升,只会被创建一次,在渲染时直接复用即可。vue2无论元素是否参与更新,每次都会重新创建然后再渲染
事件侦听器缓存 默认情况下onClick会被视为动态绑定,所以每次都会追踪它的变化,但是因为是同一个函数,所以不用追踪变化,直接缓存起来复用即可
按需引入,通过treeSharking 体积比vue2.x更小
组合API(类似react hooks),可以将data与对应的逻辑写到一起,更容易理解
提供了很灵活的api 比如toRef、shallowRef等等,可以灵活控制数据变化是否需要更新ui渲染
更好的Ts支持
# React
# vue和react区别
设计理念不同
react整体上是函数式编程思想,组件使用jsx语法,all in js,将html于css全都融入javascript中,jsx语法相对来说更加灵活
vue整体思想,是拥抱经典的html(结构)+css(表现)+js(行为)的形式,使用template模板,并提供指令供开发者使用,如v-if、v-show、v-for等,开发时有结构、表现、行为分离的感觉
数据是否可变
vue的思想是响应式的,通过Object.defineProperty或proxy代理实现数据监听,每一个属性添加一个dep对象(用来存储对应的watcher),当属性变化的时候,通知对应的watcher发生改变
react推崇的是数据不可变,react使用的是浅比较,如果对象和数据的引用地址没有变,react认为该对象没有变化,所以react变化时一般都是新创建一个对象
更新渲染方式不同
当组件的状态发生变化时,vue是响应式,通过对应的watcher自动找到对应的组件重新渲染
react需要更新组件时,会重新走渲染流程,通过从根节点开始遍历,dom diff找到需要变更的节点,更新任务还是很大,需要使用到Fiber,将大人物分割为多个小任务,可以中断和回复,不阻塞主进程执行高优先级任务
各自优势不同
vue的优势包括:框架内部封装的多,更容易上手,简单的语法及项目创建,更快的渲染速度和更小的体积
react的优势包括:react更灵活,更接近原生的js、可操作性强,对于能力强的人,更容易早出更个性化的项目
React与Vue对比 (opens new window)
关于Vue和React区别的一些笔记 (opens new window)
# react Hooks
可以在函数式组件中,获取state、refs、生命周期钩子等特性
使用规则
- 只在最顶层使用Hook,Hokks底层使用链表存储数据,按照定义的useState顺序存储对应的数据,不要在循环、条件或嵌套函数中调用hook,否则hooks的顺序会错乱
- 自定义Hook必须以『use』开头,如useFriendStatus
- 在两个组件中使用相同的Hook不会共享state,每次使用自定义Hook时,其中的所有state和副作用都是完全隔离的
React hooks原理 (opens new window)
# 为什么vue和react都选择了Hooks
更好的状态复用
对于vue2来说,使用的是mixin进行混入,会造成方法与属性的难以追溯。 随着项目的复杂,文件的增多,经常会出现不知道某个变量在哪里引入的,几个文件间来回翻找, 同时还会出现同名变量,相互覆盖的情况……😥
更好的代码组织
vue2的属性是放到data中,方法定义在methods中,修改某一块的业务逻辑时, 经常会出现代码间来回跳转的情况,增加开发人员的心智负担
使用Hooks后,可以将相同的业务逻辑放到一起,高效而清晰地组织代码
告别this
this有多种绑定方式,存在显示绑定、隐式绑定、默认绑定等多种玩法,里边的坑不是一般的多
vue3的setup函数中不能使用this,不能用挺好,直接避免使用this可能会造成错误的
# React Fiber
解决react旧版本,页面卡段时候出现丢帧卡顿问题
# React旧版本问题
当我们调用setState更新页面的时候,React会遍历应用的所有节点,计算出差异,然后在更新UI
整个过程一气呵成,不能被打断。如果页面元素很多,这个过程执行的时间可能超过50毫秒,就容易出现掉帧的现象
# 新版本解决方案
React Fiber是把一个大任务拆分为很多个小块的任务,一个小块任务的执行必须是一次完成的,不能出现暂停,但是一个小块任务执行完后可以移交控制权给浏览器响应用户操作
核心是通过requestIdleCallback,会在利用浏览器空闲时间找出所有需要变更的节点
阶段一,生成Fiber树,得出需要更新的节点信息,这一步是一个渐进的过程,可以被打断
阶段二,将需要更新的节点一次性批量更新,这个过程不能被打断
# React中使用了Fiber,为什么vue没有使用Fiber?
原因是二者的更新机制不一样
Vue是基于template和watcher的组件级更新,把每个更新任务分割的足够小,不需要使用Fiber架构,将任务进行更细粒度的拆分
React是不管在哪里调用setState,都是从根节点开始更新,更新任务还是很大,需要用到Fiber将大任务分割为多个小任务,可以中断和恢复,不阻塞主进程执行高优先级的任务,如果不用Fiber,会出现老版本卡顿问题
# 为什么React推行函数式组件
- 函数组件不需要声明类,可以避免大量的譬如extends或者constructor这样的代码
- 函数组件不需要处理this指向问题
- 函数组件更贴近于函数式编程,更加贴近react的原则。使用函数式编程,灵活度更高,更好的代码复用
- 随着Hooks功能强大,更推动了函数式组件+Hooks这对组合的发展 为什么 React 现在要推行函数式组件,用 class 不好吗? (opens new window)
函数式组件 && React Hook (opens new window)
# useMemo和useCallback的作用与区别
# useCallback
useCallback返回一个函数,只有在依赖项发生变化的时候才会更新(返回一个新的函数),多用于生成一个防抖函数
注意:组件每次更新时,所有方法都会重新创建,这样之前写的防抖函数就会失效,需要使用useCallback包裹
import {debounce} from 'debounce';
// 第二个参数为要监听的变量,当为空数组时[],submit只会被创建一次
// 当监听有值时,会随着值的变化重新创建生成新的submit
const submit = useCallback(debounce(fn, 2000), [])
<button onClick={() => submit()}>提交</button>
# useMemo
useMemo只有依赖项发生改变的时候,才会重新调用此函数,返回一个新的值,类似于vue中的Computed计算属性
const info = useMemo(() => {
// 定义info变量,该变量会随着inputPerson,inputAge的变化而变化,info可以在页面中显示
return {
name: inputPerson,
age: inputAge
}
}, [inputPerson, inputAge])
详解React useCallback & useMemo (opens new window)
# setState是同步还是异步?
首先,同步和异步主要取决于它被调用的环境
这里的同步还是异步,指的是调用setState方法后,是否能立刻拿到更新后的值
如果setState在React能够控制的范围被调用,它就是异步的。比如合成事件处理函数、生命周期函数
在合成事件和钩子函数中,多次调用setState修改同一个值,只会取最后一次的执行,前面的会被覆盖
如果setState在原生Javascript控制的范围被调用,它就是同步的。比如原生事件处理函数、setTimeout、promise的回调函数
在原生事件和异步中,可以多次调用setState 修改同一个值,每次修改都会生效
# react中的合成事件和原生事件
react为了解决跨平台,兼容性问题,自己封装了一套事件机制,代理了原生的事件,像在jsx中常见的onClick、onChange这些都是合成事件
原生事件是指非react合成事件,原生自带的事件监听addEventListener,或者也可以用原生js、jq直接绑定事件的形式都属于原生事件
# JSX语法
- jsx是React.createElement(component, props, ...children)函数的语法糖
- 底层是使用babel-plugin-transform-react-jsx插件将jsx的语法转成js对象,判断是否是jsx对象或者是否是一个组件,转换为对应的js对象(虚拟dom)
// 示例一
<MyButton color="blue" shadowSize={2}>Chick Me</MyBotton>
// 会编译为
React.createElement(MyBotton, {color: 'blue', shadowSize:2 }, 'Chick Me')
// 示例二:
// 以下两种示例代码完全等效
const element = (<h1 className='greet'>Hello</h1>)
// 等价于
const element = React.createElement('h1', {className:"greet"}, 'Hello')
# 服务端渲染
# 服务器渲染的多重模式
传统的spa应用,都属于CSR(Client Side Rendering)客户端渲染
主要问题
- 白屏时间过程:在JS bundle返回之前,加入bundle体积过大或者网络条件不好的情况下,页面一直是空白的,用户体验不好
- SEO不友好:搜索引擎访问页面时,只会看HTML中的内容,默认是不会执行JS,所以赚取不到页面的具体内容
服务端渲染的多种模式
SSR(Server Side Rendering),即服务端渲染
服务端直接实时同构渲染当前用户访问的页面,返回的HMTL包含页面具体内容,提高用户的体验
适用于:页面动态内容,SEO的诉求、要求首屏时间快的场景
缺点: SSR需要较高的服务器运维成本、切换页面时较慢,每次切换页面都需要服务端新生成页面
SSG(Static Site Generation),是指在应用编译构建时预先渲染页面,并生成静态HTML
把生成的HTML静态资源部署到服务器后,浏览器不仅首次能请求到带页面内容的HTML,而且不需要服务端实时渲染,大大节约了服务器运维成本和资源
适用于:页面内容由后端获取,但变化不频繁,满足SEO 的诉求、要求首屏时间快的场景,SSG打包好的是静态页面,和普通页面部署一样
ISR(Incremental Static Regeneration),创建需要增量静态再生的页面
创建具有动态路由的页面(增量静态再生),允许在应用运行时再重新生成每个页面HTML,而不需要重新构建整个应用,这样即使有海量页面(比如博客、商品介绍也等场景),也能使用SSG的特性
在Next.js,使用ISR需要getStaticPaths 和getStaticProps同时配合使用
你知道吗?SSR、SSG、ISR、DPR 有什么区别? (opens new window)
什么是SSR/SSG/ISR?如何在AWS上托管它们? (opens new window)
# vue SSR服务端渲染
# ssr原理
通过asyncData获取数据,获取数据成功后,通过vue-server-renderer将数据渲染到页面中,生成完整的html内容,实现服务端渲染
# SSR基本交互流程
- 在浏览器访问首页时,Web服务器根据路由拿到对应数据渲染并输出html,输出的html包含两部分
- 路由页对应的页面及已渲染好的数据(后端渲染)
- 完整的SPA程序代码
- 在客户端首屏渲染完成之后,其实已经是一个和之前SPA相差无几的应用程序了,接下来我们进行的任何操作只是客户端的应用进行交互
# vue SSR整体流程
- 配置两个入口文件,一个是客户端使用,一个是服务端使用,一套代码两套执行环境
- 服务端渲染需要Vue实例,每一次客户端请求页面,服务端渲染都是用一个新的vue实例,服务端利用工厂函数每次都返回一个新的vue实例
- 获取请求页面的路由,生成对应的vue实例
- 如果页面中需要调接口获取数据,通过asyncData获取数据,数据获取成功后,通过异步的方式在继续进行初始化,通过vue-server-renderer将数据渲染到页面中,生成html内容
# 如何避免客户端重复请求数据
在服务端已经请求的数据,在客户端应该避免重复请求,怎样同步数据到客户端?
通过(window对象作为中间媒介进行传递数据)
- 服务端获取数据,保存到服务端的store状态,以便渲染时候使用,最终会将store保存到window中
- 在renderer中会在html代码中添加
<script>window.__INITIAL_STATE__ = context.state</script>, <!-- 在解析页面的时候会进行设置全局变量 --> - 在浏览器进行初始化Store的时候,通过window对象进行获取数据在服务端的状态,并且将其注入到store.state状态中,这样能够实现状态统一
# 为什么服务端渲染不能调用mounted钩子
服务端渲染不能调用beforeMount和mounted,Node环境没有document对象,初始化的时候,vue底层会判断当前环境中是否有el这个dom对象,如果没有,就不会执行到beforeMount和mounted这两个钩子函数
Vue 服务端渲染(SSR) (opens new window)
理解Vue SSR原理,搭建项目框架 (opens new window)
# React Next预渲染模式
Next.js支持SSR、SSG、ISR三种模式,默认是SSG
SSR模式
需要将Next.js应用程序部署到服务器,开启服务端渲染
整个流程:用户访问页面->如果该页面配置了getServerSideProps函数->调用getServerSideProps函数->用接口的数据渲染出完整的页面返回给用户
// 定义页面 function Page({data}) { // Render data... } // 如果该页面配置了getServerSideProps函数,调用该函数 export async function getServerSideProps() { // 请求接口拿到对应的数据 const res = await fetch('https://.../data'); const data = await res.join(); // 将数据渲染到页面中 return { props: { data }} } // 导出整个页面 export default PageSSG模式
SSG模式:项目在打包时,从接口中请求数据,然后用数据构建出完整的html页面,最后把打包好的静态页面,直接放到服务器上即可。
Next.js允许你从同意文件export(导出)一个名为getStaticProps的async(异步)函数。该函数在构建时候被调用,并允许你在预渲染时将获取的数据作为props参数传递给页面
// 定义Blog页面 function Blog({posts}) { // Render posts... } // getStaticProps函数,在构建时候被调用 export async function getStaticProps() { // 调用外部API获取博文列表 const res = await fetch('https://...//posts'); const posts = await res.json(); // 通过返回{ props: {posts}} 对象 Blog组件 // 在构建时将接收到的posts参数 return { props: { props: { posts, } } } } export default Blog
ISR模式
创建具有动态路由的页面,用于海量生成
Next.js允许在应用运行时在重新生成每个页面HTML,而不需要重新构建整个应用。这样即使有海量页面,也能使用上SSG的特性。一般来说,使用ISR需要getStaticPaths和getStaticProps同时配合使用
// 定义博文页面 function Blog({ post }) { // Render post... } // 此函数在构建时被调用 export async function getStaticPaths() { // 调用外部 API 获取博文列表 const res = await fetch('https://.../posts') const posts = await res.json() // 据博文列表生成所有需要预渲染的路径 const paths = posts.map((post) => ({ params: { id: post.id }, })) return { paths, fallback: false } } // 在构建时也会被调用 export async function getStaticProps({ params }) { // params 包含此片博文的 `id` 信息。 // 如果路由是 /posts/1,那么 params.id 就是 1 const res = await fetch(`https://.../posts/${params.id}`) const post = await res.json() // 通过 props 参数向页面传递博文的数据 return { props: { post } } } export default Blog
使用Next.js进行增量静态再生(ISR)的完整指南 (opens new window)
# Node
Node经常用于前端构建、微服务、中台等场景
# Node 高并发的原理
Node的特点:事件驱动、非阻塞I/O、高并发
# node高并发的原理
Nodejs之所以单线程可以处理高并发的原因,得益于内部的事件循环机制和底层线程池实现
遇到异步任务,node将所有的阻塞操作都交给了内部的线程池去实现。本质上的异步操作还是由线程池完成的,主线程本身只负责不断的往返调度,从而实现异步非阻塞I/O,这边是Node单线程和事件驱动的精髓之处
# 整体流程
- 每个Node进程只有一个主线程在执行程序代码
- 当用户的网络请求、数据库操作、读取文件等其他的异步操作时候,node会把它放到Event Queue('事件队列')之中,此时并不会立即执行它,代码也不会被阻塞,继续往下走,直到主线程代码执行完毕
- 主线程代码执行完毕完成后,然后通过事件循环机制,依次取出对应的事件,从线程池中分配一个对应的线程去执行,当有事件执行完毕后,会通知主线程,主线程执行回调拿到对应的结果
# Node事件循环机制与浏览器的区别
主要区别:浏览器中的微任务是在每个相应的宏任务中执行的,而nodejs的微任务是在不同阶段之间执行的
node事件循环机制分为6个阶段,他们会按照顺序反复执行
每当进入某一阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或执行的回调函数数量达到系统设置的阀值,会进入下一阶段

主要介绍timers、poll、check这3个阶段,因为日常开发中的绝大部分异步任务都是在这3个阶段处理的
timer
timers阶段会执行setTimeout和setInterval回调,并且是由poll阶段控制的
poll
poll是一个至关重要的阶段,这一阶段中,系统会做两件事情:回到timer阶段执行回调,执行I/O回调
check阶段
setImmediate()回调会被加入check队列中,从event loop的阶段图可以知道,check阶段的执行顺序在poll阶段之后
面试题:说说事件循环机制(满分答案来了) (opens new window)
浏览器与Node的事件循环(Event Loop)有何区别? (opens new window)
# 中间件原理
比较流行的Node.js框架有Express、Koa和Egg.js,都是基于中间件来实现的。中间件主要用于请求拦截和修改请求或响应结果
node中间件本质就是在进入具体的业务处理之前,先让特定过滤器进行处理。
一次HTTP请求通常包含很多工作,如果请求体解析、Cookie处理、权限验证、参数验证、记录日志、ip过滤、异常处理,这些环节通过中间件处理,让开发人员把核心放在对应的业务开发上
这种模式也被称为"洋葱圈模型"

模拟一个中间件流程
const m1 = async next => {
console.log('m1 run');
await next();
console.log('result1')
}
const m2 = async next => {
console.log('m2 run');
await next();
console.log('result2')
}
const m3 = async next => {
console.log('m3 run');
await next();
console.log('result3')
}
const middlewares = [m1, m2, m3]
function useApp() {
const next = ()=> {
const middleware = middleware.shift();
if(middleware) {
return Promise.resolve(middleware(next));
} else {
return Promise.resolve('end')
}
}
next();
}
// 启动中间件
useApp();
// 依次打印
// m1 run
// m2 run
// m3 run
// result3
// result2
// result1
express中间件的执行过程
const express = require('express');
const app = express();
app.listen('3000', () => {
console.log('启动服务')
})
app.use((req, res, next) => {
console.log('first');
next();
console.log('end1')
})
app.use((req, res, next) => {
console.log('second');
next();
console.log('end2')
})
app.use((req, res, next) => {
console.log('third');
next();
console.log('end3')
})
app.get('/', (req, res) => {
res.send('express')
})
// 请求http://localhost:3000/#/
// 依次打印:
// first
// second
// third
// end3
// end2
// end1
express常用的中间件
中间件名称 作用 express.static() 用来返回静态文件 body-parser 用来解析post数据 multer 处理文件上传 cookie-parser 用来操作cookie cookie-session 处理session
深入浅出node中间件原理 (opens new window)
nodejs 中间件理解 (opens new window)
# 实现一个大文件上传和断点续传
该案例会使用node对文件进行操作,这也是node最常用的场景之一
其中一个关键的知识点:pipe管道流
管道:一个程序的输出直接成为下一个程序的输入,就像水流过管道一样方便
readStream.pipe(writeStream)就是在可读流与可写流中间加入一个管道,实现一遍读取,一边写入,读一点写一点
管道流的好处:节约内存
读出的数据,不做保存,直接流出。写入写出会极大的占用内存,stream可以边读边写,不占用太多内存,并且完成所需任务
字节跳动面试官:请你实现一个大文件上传和断点续传 (opens new window)
# 如何做到接口防刷
第一步:负载均衡层的限流,防止用户重复抽象
在负载均衡设备中做一些配置,判断如果同一个用户在1分钟之内多次发送请求来进行抽奖,就认为是恶意重复抽奖,或者是他们自己写的脚本在刷
这种流量一律认为是无效流量,在负载均衡那个层就给直接屏蔽掉。所以这里就可以把无效流量给拦截掉
第二步:暴力拦截浏览
其实秒杀、抢红包、抽奖,这类系统有一个共同的特点,那就是假设有50万请求涌入进来,可能前5万请求就直接把事儿干完了,甚至是前500请求就把事儿干完了
后续的几十万流量是无效的,不需要让他们进入后台系统执行业务逻辑了
这样的话,其实在负载均衡这一层(可以考虑用Nginx之类的来实现)就可以拦截掉99%的无效流量
第三步: ip或用户抽象次数校验
建立一个抽奖表,该表记录所有参与抽奖的ip和用户信息,比如判断5s内,该用户连续抽奖了2次以上,就拒绝该请求,认为是在刷接口,就把该用户和ip加入黑名单
如何设计一个百万级用户的抽奖系统? (opens new window)
# mongoDb和mySQL的区别
mongoDb是非关系型数据库,mySQL是关系型数据库
mongoDb里存储的是json格式的数据,键值对形式,该数据结构非常符合前端的需求。
关系型数据天然就是表格式的,就是后端常说的"表",数据存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据
对事务性的支持不同
mongoDb不支持事务,mySQL支持事务
事务的好处便于回滚,如第一个账户划出款项必须保证正确的存入第二个账户,如果第二个环节没有完成,整个的过程都应该取消,否则就会发生丢失款的问题。这时就需要回滚,恢复到初始的状态
# 高并发的如何正确修改库存
场景
抽象或秒杀活动,同时一千个请求过来,但奖品库存只有一个,期望的结果是只有一个人中奖,剩下999个人没有中奖。
但是压测时,遇到的情况却是1000个都中奖了,并且库存还是一个
原因就是高并发时,一千个请求同时读到库存都是一个,都中奖后,库存同时减一,最后导致库存没有减对
解决此类问题,就是要给数据库加锁的概念,保证库存一个一个减、串行的减,解决方式就是使用mongoDB中的update方法减库存
mongoDb中,有三种方法可以实现更新数据
- save方法,如db.collection.save(obj),save是在客户端代码中生成的对象,需要从客户端回写到服务端
- findOneAndUpdate方法,如db.findOneAndUpdaet(<filter>,{obj}),和save类似也需要从客户端回写到服务端
- update方法,如db.update(<filter>{obj}),update是服务端处理的,速度最快;实测当并发超过1000次每秒时,update的速度是其他的2倍
# Redis
Redis特点
- Redis也是一种数据库,Redis中的数据是放到内存中的,Redis查询速度极快。一些常用的数据,可以存到Redis中,缩短从数据库查询数据的时间。
- Redis可以设置过期时间,可以将一些需要定期过期的信息放到Redis中,有点类似cookie
运用场景
- 将经常查询的信息存储到redis中,如抽奖活动的配置信息,这些信息查询的频率最高,放到Redis中可以提高查询速度,还可以存储用户的个人信息(权限、基础信息等)
- 需要设置过期时长的信息,如微信授权,每2个小时过期一次,将对应的授权code存进去,到时删除
优点
支持多重数据类型
持久化存储
作为一个内存数据库,最担心的,就是万一机器死机宕机,数据就会消失掉。redis使用RDB和AOF做数据的持久化存储。主从数据同时,生成rdb文件,并利用缓冲区添加新的数据更新操作做对应的同步。
性能很好
缺点
- 由于是内存数据库,所以单台机器存储的数据量跟机器本身的内存有关
- 如果进行完成重同步,需要生成rdb文件,并进行传输,会占用主机的CPU,并会小号现网的带宽。
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久,在这个过程中,redis不能提供服务
# node创建子进程
当项目中需要大量计算的操作的时候,就要考虑开启多进程来完成了,类似于web worker (opens new window),否则会阻塞主线程的执行
Node提供了 child_process 模块来创建子进程
进程间通信:使用fork方法创建的子进程,可通过send、on(message)方法来发送和接收进程间的数据
// parent.js
const cp = require('child_process');
// 通过child_process中的fork方法来生成子进程
let child = cp.fork('child.js');
child.send({ message: 'from_parent'}); // send方法发送数据
child.on('message', res => console.log(res)); // on 方法接收数据
// child.js
process.on('message', res => console.log(res));
process.send({ message: 'from_child' });
Nodejs进阶:如何玩转子进程(child_process) (opens new window)
# PM2
PM2可以根据cpu核数,开启多个进程,充分利用cpu的多核性能
如pm2 start app.js -i 8 该命令可以开启8个进程
主要作用
- 内建负载均衡(使用 Node Cluster 集群模块)
- 线程守护,keep alive
- 0秒停机重载,维护升级的时候不需要停机
- 停止不稳定的进程(避免无限循环)
负载均衡cluster的原理
- Node.js给我们提供了 cluster模块,它可以生成多个工作线程来共享同一个TCP连接
- 首先,Cluster会创建一个master,然后根据你指定的数量复制出多个 server app(也被称为工作线程)
- 它通过IPC通道与工作线程之间进行通信,并使用内置的负载均衡来更好的处理线程之间的压力,该负载均衡使用了Round-robin算法(也被称为循环算法)
使用PM2将Node.js的集群变得更加容易 (opens new window)
# 计算机网络与安全
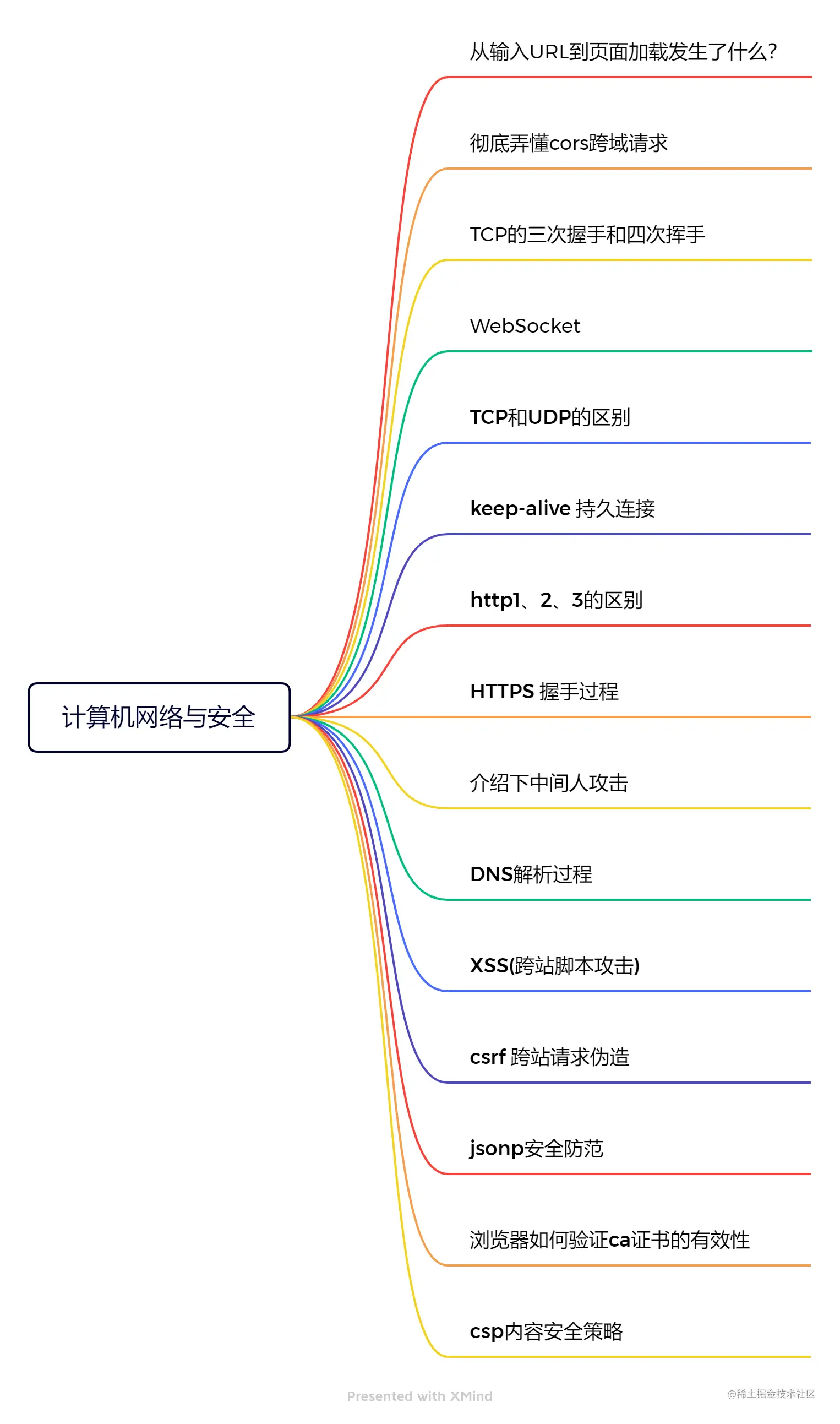
# 从输入URL到页面加载发生了什么?
浏览器查找当前URL是否存在缓存,并比较缓存是否过期.(先判断HTTP请求浏览器是否已缓存)
有缓存
- 如为强制缓存,通过Expires或Cache-Control:max-age判断该缓存是否过期,未过期,直接使用该资源;Expires和max-age,如果两者同事存在,则被Cache-Control的max-age覆盖
- 如为协商缓存,请求头上带上相关信息 If-none-match(Etag)与If-modified-since(last-modified),验证缓存是否有效,若有效则返回状态码304,若无效则重新返回资源,状态码为200
DNS解析URL对应的IP(DNS解析流程见下文)
根据IP简历TCP连接(三次握手)(握手过程见下文)
HTTP发起请求
服务器处理请求,浏览器接收HTTP响应
渲染页面,构建DOM树
- HTML解析,生成DOM树
- 根据CSS解析生成CSS树
- 结合CSS树和DOM树,生成渲染树
- 根据渲染树计算每一个节点的信息(layout布局)
- 根据计算好的信息绘制页面
如果遇到script标签,则判断是否含有defer或者async属性,如果有,异步去下载该资源;如果没有设置,暂停dom的解析,去加载script资源,然后执行该js代码(script标签加载和执行会阻塞页面的渲染)
关系TCP连接(四次挥手)(挥手过程见下文)
从输入url到页面加载完成发生了什么详解 (opens new window)
在浏览器输入 URL 回车之后发生了什么(超详细版) (opens new window)
# 彻底弄懂cors跨域请求
cors是解决跨域问题的常见解决方法,关键是服务器要设置Access-Control-Allow-Origin,控制那些域名可以共享资源
origin是cors的重要标识,只要是非同源或者POST请求都会带上Origin字段,接口返回后服务器也可以将Access-Control-Allow-Origin设置为请求的Origin,解决cors如何指定多个域名的问题
cors将请求分为简单请求和非简单请求
简单请求
- 支持持HEAD、get、post请求方式
- 没有自定义的请求头
- Content-Type;只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
对于简单请求,浏览器直接发出cors请求。具体来说,就是在头信息之中,增加一个Origin字段。如果浏览器发现这个接口回应的头信息没有包含Access-Control-Allow-Origin字段的话就会报跨域错误
非简单请求的跨域处理
非简单请求,会在正式通信之前,增加一个HTTP查询请求,成为"预检"请求(options),用来判断当前网页所在的域名是否在服务器的许可名单之中。
如果在许可名单中,就会发正式请求;如果不在,就会报跨域错误。
注:新版chrome浏览器看不到OPTIONS预检请求,可以网上查找对应的查看方法
跨域资源共享CORS详解 (opens new window)
# TCP的三次握手和四次挥手
# WebSocket
WebSocket是HTML5提供的一种浏览器与服务进行全双工通讯的网络协议,属于应用层协议,WebSocket没有跨域限制。
相比于接口轮训,需要不断的建立http连接,严重浪费了服务器端和客户端的资源
WebSocket基于TCP传输协议,并复用HTTP的握手通道。浏览器和服务器只需要建立一次http连接,两者之间可以创建持久性的连接,并进行双向数据传输
缺点
websocket不稳定,要建立心跳检测机制,如果断开自动连接
手摸手教你使用WebSocket[其实WebSocket也不难] (opens new window)
socket 及 websocket的握手过程 (opens new window)
# TCP和UDP的区别
相同点:UDP协议和TCP协议都是传输层协议
不同点:
TCP面向有连接;UDP:面向无连接
TCP是要提供可靠、面向连接的传输服务。TCP在建立通信钱,必须建立一个TCP连接,之后才能传输数据。TCP建立一个连接需要3次握手,断开连接需要4次挥手,并且提供超时重发,丢弃重复数据,校验数据,流量控制等功能,保证数据从一端传到另一端
UDP不可靠性,只是把应用程序传给IP层的数据报发送出去,但是不能保证他们能达到目的地
应用场景
TCP效率要求相对低,但是对准确性要求相对高的场景。如常见的接口调用、文件传输、远程登录等
UDP效率要求相对高,对准确性要求相对低的场景,如在线视频、网络语音电话等
面试题:UDP&TCP的区别 (opens new window)
TCP和UDP的区别及应用场景 (opens new window)
# keep-alive 持久连接
keep-alive又叫持久连接,它通过重用一个TCP连接来发送/接收多个HTTP请求,来减少创建/关闭多个TCP连接的开销,启动Keep-Alive模式性能更高
在HTTP1.1协议中默认开启,可以在请求头上看到Connection:keep-alive开启的标识
在HTTP1.0中非KeepAlive模式时,每次请求都要新建一个TCP请求,请求结束后,要关闭TCP连接。效率很低。
注意:持久连接采用阻塞模式,下次请求必须等到上次响应返回后才能发起,如果上次的请求还没返回响应内容,下次请求就只能等着(就是常说的线头阻塞)
HTTP keep-alive二三事 (opens new window)
# HTTP1、2、3的区别
http1、2的区别
二进制传输,HTTP/2采用二进制格式传输数据,而非HTTP/1.X纯文本形式的报文,二进制协议解析起来更高效
Hearder压缩--HTTP/1.X的请求和响应头部带有大量信息,而且每次请求都要重复发送。HTTP2在客户端和服务器端使用"首部表"来跟踪和存储之前发送的键-值对,对于相同的数据,不在每次请求和响应发送
多路复用
就是在一个TCP连接中可以发送多个请求,可以避免HTTP旧版本中的线头阻塞问题(下次请求必须等到上次相应返回后才能发起)
这样某个请求任务耗时严重,不会影响到其他连接的正常执行,极大的提高传输性能
在HTTP/2中,有两个非常重要的概念,分别是帧(frame)和流(steam)。帧代表最小的数据单位,每个帧回表示出该帧属于哪个流(即请求),通过重新排序还原请求
服务端推送:这里的服务端推送,是指把客户端所需要的CSS/JS/IMG资源伴随着index.html,一起发送到客户端,省去了客户端重复请求的步骤
HTTP3.0的区别
http协议是应用层协议,都是建立在传输层之上的。2.0和1.0都是基于TCP的,而Http3.0则是建立在UDP的基础上
HTTP3.0新特性
- 多路复用,彻底解决TCP中队头阻塞的问题
- 集成了TLS加密功能
- 向前纠错机制
HTTP1、2、3总结
- HTTP1.1有两个主要缺点:安全不足和性能不高
- http2完全兼容http1,是更安全的HTTP、更快的HTTPS",头部压缩、多路复用等技术可以充分利用带宽,降低延迟,从而大幅度提高上网体验
- QUIC 基于 UDP 实现,是 HTTP/3 中的底层支撑协议,该协议基于 UDP,又取了 TCP 中的精华,实现了即快又可靠的协议
解密HTTP/2与HTTP/3 的新特性 (opens new window)
# HTTPS握手过程
https采用非对称加密 + 对称加密,非对称加密来传递秘钥;对称加密来加密内容
- 客户端使用https的url访问web服务器,要求与服务器建立ssl连接
- 服务器收到客户端请求后,会将网站的证书(包含公钥)传送一份给客户端
- 客户端收到网站证书后会检查证书的颁发机构以及过期时间,如果没有问题就随机产生一个秘钥
- 客户端利用公钥将会话秘钥加密,并传送给服务端
- 服务端利用自己的私钥解密出会话秘钥,之后服务器会客户端使用秘钥加密传输
加密速度对比
对称急吗解密的速度比较快,适合数据比较长时的使用
非对称加密和解密话费的时间长、速度相对较慢,只适合对少量数据的使用
非对称加密: 有公钥私钥,公钥加密,私钥加密;对称加密:同一个秘钥进行加密和解密
# http 与 https 默认端口号
- HTTP 默认端口号: 80
- HTTPS 默认端口号: 443
当客户端与服务器进行HTTP通信时,默认情况下会使用端口号80进行通信。例如,如果你在浏览器中输入http://example.com,则浏览器会默认使用80端口发送http请求给服务器。
当客户端与服务器进行HTTPS通信时,默认情况下会使用端口号443进行加密通信。HTTPS通过使用SSL(Secure Sockets Layer)或TLS(Transport Layer Security)协议对通信进行加密和认证,以确保数据传输的安全性。例如,如果您在浏览器中输入 https://example.com, 则浏览器会默认使用443端口发送HTTPS请求给服务器
请注意,虽然这些是默认端口号,但是在实际应用中,可以通过显式指定不同的端口号来进行自定义配置。例如,有时会在非标准端口上部署HTTP或HTTPS服务,以满足特定的需求。
# 介绍下中间人攻击
过程
- 客户端向服务器发送建立连接的请求
- 服务器向客户端发送公钥
- 攻击者劫获公钥,保留在自己手上
- 然后攻击者生产一个【伪造的】公钥,发送客户端
- 客户端收到伪造的公钥后,生成加密的秘钥值发送给服务器
- 攻击者获得机密密钥,用自己的私钥及诶获得密钥
- 同时生成假的加密秘钥,发送服务器
- 服务器使用四月解密获得假秘钥
- 服务器用假秘钥加密传输信息
防范方法
服务器在发送浏览器的公钥中加入CA证书,浏览器可以验证CA证书的有效性
介绍下HTTPS中间人攻击 (opens new window)
# DNS解析过程
DNS叫做域名系统,是域名和对应ip地址的分布式数据库。有了它,就可以用域名来访问对应的服务器。
过程
在浏览器中输入url后,会优先在浏览器dns缓存中查找,如果有缓存,则直接响应用户的请求
如果没有要访问的域名,就继续在操作系统的dns缓存中查找,如果也没有,最后通过本地的dns服务器查到对应的ip地址。
DNS 服务器完整的查询过程
本地DNS服务器向根域名服务器发送请求,根域名服务器会返回一个所查询域的顶级域名服务器地址
本地DNS服务器向顶级域名服务器发送请求,接受请求的服务器查询自己的缓存,如果有记录,就返回查询结果,如果没有就返回相关的下一级权威域名服务器的地址。
本地DNS服务器向权威域名服务器发送请求,权威域名服务器返回对应的结果
本地DNS服务器将返回结果保存在缓存中,便于下次使用
本地DNS服务器将返回结果返回给浏览器
DNS解析
DNS Prefetch 是一种DNS预解析技术,当你浏览网页时,浏览器会在对网页中的域名进行解析缓存,这样当页面中需要加载该域名的资源时候就无需解析,减少用户等待时间,提高用户体验
<link ref="dns-prefetch" href="//hhh.images.test.com.cn"/>