# 框架
- vue双向绑定原理
- computed/watch区别
- vue watch类型
- v-model在自定义组件的应用
- v-mixins的用法及原理
- vuex的用法
# Javascript
- promise问题--并发限制,all,promise.all只输出resovle的
- http1,http2区别
- url从浏览器输入到渲染过程
- 缓存协商缓存
- form表单请求 enctype类型
- Object.freeze冻结
- Event loop相关问题
- egg和koa有什么优势
- 普通函数 构造函数区别
1.构造函数也是一个普通函数,创建方式和普通函数一样,但构造函数习惯首字母大写
2.构造函数和普通函数的区别在于:调用方式不一样,作用也不一样(构造函数用来新建实例对象)
3.调用方式不一样
- 普通函数的调用方式:直接调用person();
- 构造函数的调用方式:需要实用new关键字调用new Person();
4.构造函数的函数名与类名相同:Person()这个构造函数,Person即是函数名,也是这个对象的类名
5.内部用this来构造函数属性和方法
function Person(name, job,age) {
this.name = name;
this.job = job;
this.age = age;
this.sayHi = function() {
alert('HI')
}
}
6.构造函数的执行流程
- 立即在堆内存中创建一个新的对象
- 将新建的对象设置为函数中的this;
- 逐个执行函数中的代码
- 将新建的对象作为返回值
7.普通函数例子:因为没有返回值,所以undedined
function Person() {}
var p = new Person();
console.log(p)
8.用instanceof可以检查一个对象是否是一个类的实例,是则返回true;所有对象都是Object对象的后代,所以任何对象和Object做instanceof都会返回true
箭头函数this
快数组&慢数组 参考文档
Map/Set区别
**Set结构是类似于数据结构,但是成员都是不重复的值
缺点是没办法像数组一样通过下标取值的方法。
构造:
let set = new Set([1,2,3]);
set.size //3
//数组去重
let arr = [1,2,3,4,5,4,23,1,3];
arr = Array.from(new Set(arr));//[1,2,3,4,5,23]
Map结构是键值对集合(Hash结构)
//构造
const map = new Map([
['name','张三'],
['title', 'Author']
])
map.size //2
map.has('name')// true;
map.get('name')//'张三'
add(value):添加某个值,返回Set结构本身。
delete(value):删除某个值,返回一个布尔值,表示删除是否成功。
has(value):返回一个布尔值,表示该值是否为Set的成员。
clear():清除所有成员,没有返回值。
# 其他
- 视频直播问题
- document type---html XHTML
- 边缘计算
- div左右两半
- x的n次方时间复杂度
- 骨架图--puppeteer—单元测试chrome
- 设计模式
- AST和VNode区别
AST更多的是编译时生成的中间代码(包括runtime compile),而vnode则是存在于运行时的一种dom节点及其关系的抽象
# 爱奇艺面试
- veex渲染原理
- 小程序渲染原理
- splitchunk原理
- webpack按需加载原理
- App-bridge原理
# 小程序原理
小程序的框架包含两部分,分别是渲染层和AppService逻辑层,渲染层的界面使用了WebView 进行渲染;逻辑层采用JsCore线程运行JS脚本,进行逻辑处理、数据请求及接口调用等,一个小程序存在多个界面,所以渲染层存在多个WebView线程,这两个线程的通信会经由微信客户端进行中转,逻辑层把数据变化通知到渲染层,触发渲染层页面更新,渲染层把触发的事件通知到逻辑层进行业务处理。
参考文档 (opens new window)https://www.cnblogs.com/SophiaLees/p/11409339.html
小程序框架图
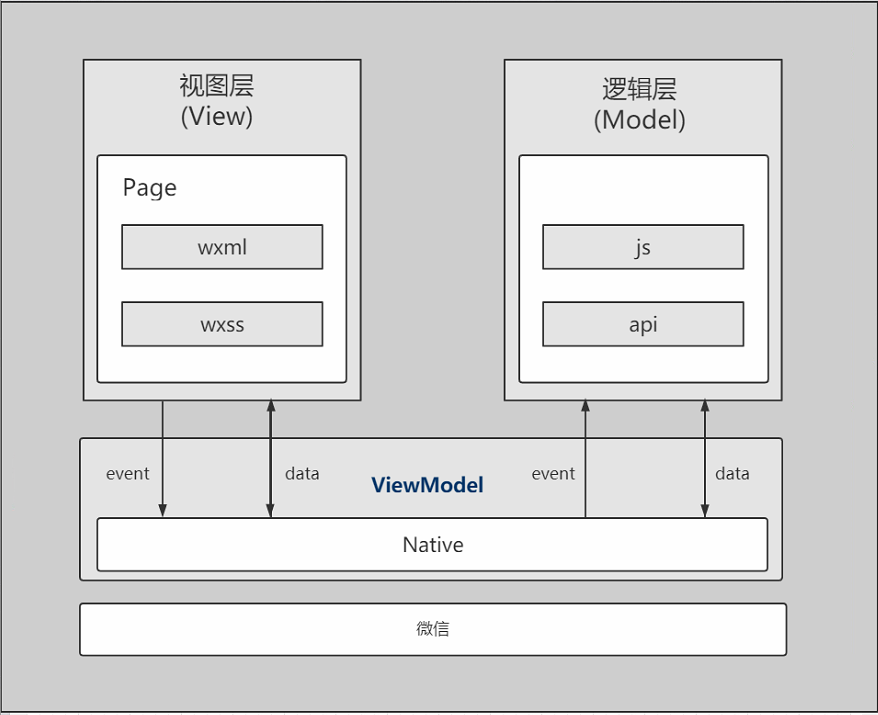
解析:
最底层是微信,当我们发版时小程序开发工具会把我们的代码和框架一起进行打包,当我们在微信里打开小程序时其实微信会把打包好的代码下载到微信app里,这样我们就可以像开发工具里一样在微信里运行我们的小程序了
native层就是小程序框架,这个框架封装了ui层组件和逻辑层组件,这些组件可以通过微信app提供的接口调用手机硬件信息。
最上层的两个框,是我们真正需要进行操作的视图层和逻辑层,视图层和逻辑层的交互是通过数据经由native层进行交互的。视图层和逻辑层都可以调用native框架封装好的组件和方法
# splitchunk原理
在大型项目的开发过程中,往往会用到很多公共库,公共库的内部不同于业务代码,在很长的一个时间周期内都不会有改动。这部分公共库通常会被打包在commonChunk中,webpack配置如下
optimization: {
splitChunks: {
minSize: 1000000,
cacheGroups: {
vendor: {
name: "common",
test: /[\\/]node_modules[\\/]/,
chunks: "initial",
minSize: 30000,
minChunks: 1,
priority: 8
}
}
}
}
这样可以把长时间不变的公共包内容打包进一个名为common的chunk中,同业务代码进行隔离,生成稳定的缓存key,一便浏览器实现缓存。但是这也带来一个问题:尽管用户端实现了缓存,但是我们在打包的时候,webpack依然会多所有用到的公共包进行遍历,解析,处理。严重影响打包速度。
webpack中的DLL打包优化,同window中的DLL的原理类似。通过另写一份打包配置,把长期不变的公共包内容单独打包,然后在业务代码打包时,通过webpack内置插件DllReferencePlugin引用之前打包的动态链接内容,而不是每次都打包同样的公共包内容,从而加快打包速度。
# 伴鱼面试
- 请写出下面代码的输出内容
console.log(1);
setTimeout(() => {
console.log(2);
Promise.resolve().then(data => {
console.log(3);
});
});
new Promise((resolve) => {
resolve()
console.log(4)
}).then(() => {
console.log(5);
setTimeout(() => {
console.log(6);
});
}).then(() => console.log(7))
console.log(8); // ==> 输出:_1,_4,8,5,2,3,6________________
//以下问答
console.log(1)
await sleep(1 * 1000)
console.log(2)
function sleep(timer){
return new Promise((resolve, reject) => {
setTimeout(resolve, timer)
})
}
const result = fetch();
const result2 = fetch({param:result.key})
var fn= async function() {
const {data} = await fetch()
this.fun(data)
}
- 输出
async function async1() {
console.log('a');
await async2();
console.log('b');
}
async function async2() {
console.log('c')
}
console.log('d');
setTimeout(() => {
console.log('e')
}, 0)
async1();
new Promise(function(resolve) {
console.log('f');
resolve();
}).then(function() {
console.log('g');
})
console.log('h')
d
a
c
f
h
b
g
undefined
e
- 请写出下面代码的输出内容
console.log(fish1,fish2,fish3);
var fish1 = function(){
console.log('welcome to Palfish-1')
}
function fish2(){
console.log('welcome to Palfish-2')
}
var fish3 = 'welcome to Palfish-3'
var fish1,fish2,fish3;
console.log(fish1,fish2,fish3); // ==> 输出:____________
- 请写出下面代码的输出内容
var nickname = "LiLei";
function Person(name){
this.nickname = name;
this.sayHi = function() {
console.log(this.nickname);
setTimeout(function(){
console.log(this.nickname);
}, 1000);
}
}
var Male = {
nickname: 'xiaofang',
sayHi: () => {
console.log(this.nickname);
}
}
var person = new (Person.bind(Male, 'XiaoHong'));
person.sayHi(); // ==> 输出:__________________
- 请写出下面代码的输出内容
let object = {a:0};
function fun(obj={a:2}) {
obj.a=1;
obj={a:2};
obj.b=2;
object = {a:2}
}
fun(object);
console.log(object); // ==> 输出:_____{a:2}_____________
5.实现如下布局,footer永远在底部显示
position:sticky//粘性布局的东东
6.二叉树中两个节点最近的公共节点
var LowastCommonAncestoor = function(root, p, q) {
if (!root || root === p || root === q) return root;
let left = LowastCommonAncestoor(root.left, p, q);
let right = LowastCommonAncestoor(root.right, p, q);
if (!left) return right;
if(!right) return left;
returnn root;
}
# node
- 介绍一下你对中间件的理解
个人理解:将具体业务和底层逻辑解耦的组件。
大致的效果是:需要利用服务的人(前端写业务的),不需要知道底层逻辑(提供服务的)的具体实现,只要拿着中间件结果来用就好了。
举个例子:我开了一家炸鸡店(业务端),然而周边有太多屠鸡场(底层),为了成本我肯定想一个个比价,再综合质量挑选一家屠鸡场合作(适配不同底层逻辑)。由于市场变化,合作一段时间后,或许性价比最高的屠鸡场就不是我最开始选的了,我又要重新和另一家屠鸡场合作,进货方式、交易方式等等全都要重来一套(重新适配)。
然而我只想好好做炸鸡,有性价比高的肉送来就行。于是我找到了一个专门整合屠鸡场资源的第三方代理(中间件),跟他谈好价格和质量后(统一接口),从今天开始,我就只需要给代理钱,然后拿肉就行。代理负责保证肉的质量,至于如何根据实际性价比,选择不同的屠鸡场,那就是代理做的事了。
- 怎么保证后端服务稳定性,怎么做容灾
- 多个服务器部署 - 降级处理,服务器挂了,从缓存里面获取
- 怎么让数据库查询更快
- 索引 - 如果数据量太多了可以拆表,分多个数据库
- 为什么用mysql
体积小、速度快、总体拥有成本低、开放源代码
# 头条
- 合并两个有序的链表 --- 力扣地址 (opens new window)
输入两个递增排序的链表,合并这两个链表并使新链表的节点扔点是递增排序的
示例
输入: 1->2->4, 1->3->4
输出: 1->1->2->3->4->4
//解题
var mergeTwoLists = function(l1, l2) {
if (l1 === null) {
return l2
}
if (l2 === null) {
return l2;
}
if(l1.val < l2.val) {
l1.next = mergeTwoLists(l1.next, l2);
return l1;
} else {
l2.next = mergeTwoLists(l1,l2.next);
return l2;
}
}
- DOM节点拖拽效果以及延伸
//实例
//为button元素添加点击事件,当用户点击按钮时,在id="demo"的p元素上输出'Hello world'
document.getElementById('mybtn').addEventListener('click', function() {
document.getElementById('demo').innerHTML = 'hello world'
})
addEventListener方法用于向指定元素添加事件句柄
| 参数 | 描述 |
|---|---|
| event | 必须,字符串,指定事件名 |
| function | 必须,指定要事件触发时执行的函数 |
| useCapture | 可选,布尔值,指定事件是否在捕获或冒泡阶段--- true:事件句柄在捕获节点执行;false:默认句柄在冒泡阶段执行 |
第三个参数是什么呢?这个参数涉及到事件的捕获与冒泡,为true时捕获,false为冒泡
举个🌰,我有两个div和一个button,button在div2里面,div2在div1里面,如下所示
 给button、div1、div2都添加了click事件,分别alert button、div1、div2.
给button、div1、div2都添加了click事件,分别alert button、div1、div2.
window.onload = function() {
document.getElementById('btn').addEventListener('click', function() {
//body...
alert('hello');
})
document.getElementById('div1').addEventListener('click', function() {
alert('div1');
})
document.getElementById('div2').addEventListener('click', function() {
alert('div2');
})
}
那么问题就来了,我点击了button,也相当于点击了div1和div2,那么,谁先出现呢?
直观的讲,谁在上面,谁在下面。
所以,在js中就分为了两个处理方法,冒泡和捕获。
冒泡:从里面往外面触发事件,就是alert的顺序是button、div2、div1.
捕获:从外面往里面触发事件,就是alert的顺序是div1、div2、button
要想冒泡,就要将每个监听事件的第三个参数设置为false,也就默认的值。
要想捕获,就要每个监听事件的第三个参数设置为true.
- 进程通讯 本地文档 参考文档 (opens new window)
- 进程监听同一端口